Геометрия разбора скриптов: как театральные субтитры и титры определяют диалог
Современные системы театральных субтитров зависят от одной критически важной возможности: точного обнаружения реплик из скриптов.
Независимо от того, генерируются ли титры для оперы, субтитры для сценических постановок или живые титры для обеспечения доступности, система должна надежно определять:
- Кто говорит
- Когда начинается строка
- Где в скрипте появляются блоки диалога
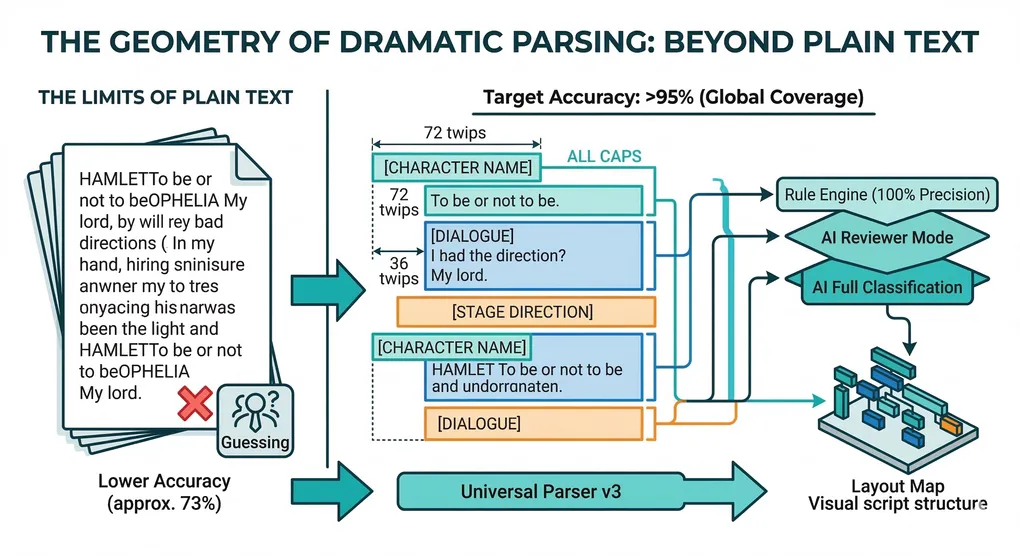
На первый взгляд, это звучит как задача обработки естественного языка. На практике это не так. В ходе разработки SurtitleLive v2 мы проанализировали около 100 скриптов на разных языках и из разных театральных традиций. Этот процесс привел нас к неожиданному выводу: театральный скрипт — это прежде всего не лингвистические данные. Это пространственные данные.
1. Проблема западного скрипта: структура без пунктуации
Типичный английский театральный скрипт полагается на соглашения о макете, а не на пунктуацию для определения ролей.
Пример: Типичный макет сценического скрипта
ГАМЛЕТ Быть или не быть, вот в чем вопрос.
ОФЕЛИЯ Мой лорд, у меня есть ваши воспоминания.
Для человека-читателя интерпретация очевидна:
| Блок | Интерпретация |
|---|---|
| ГАМЛЕТ | Имя персонажа |
| Текст с отступом | Диалог |
| ОФЕЛИЯ | Имя персонажа |
Но для парсера, который видит только простой текст, структура исчезает. Мы распознаем закономерности, потому что имена персонажей появляются ВСЕМИ ЗАГЛАВНЫМИ БУКВАМИ, диалог с отступом, а блоки разделены вертикальным интервалом. Грамматика западных скриптов типографская, а не лингвистическая.
2. От блоков скрипта к субтитрам
В среде живого выступления программное обеспечение для субтитров не просто отображает текст. Он должен преобразовать скрипт в последовательность субтитров.
Каждый обнаруженный блок диалога становится субтитром, который можно активировать во время живого выступления. Если парсер неправильно идентифицирует блок диалога, система субтитров активирует неверный субтитр — сбой, который неприемлем в живом театре.
3. Пунктуация против макета: кросс-языковое открытие
Производительность сильно варьируется в зависимости от того, насколько язык полагается на явные или неявные маркеры.
Китайский / кантонский: на основе пунктуации
Китайские театральные скрипты часто кодируют структуру явно:
АННА: Сегодня идет дождь. БОРИС: Правда? (Они смотрят в окно.)
| Шаблон | Классификация |
|---|---|
| Персонаж: реплика | Диалог |
| (...) (Скобки) | Сценическое направление |
Эта структура, основанная на пунктуации, делает разбор почти тривиальным по сравнению с западными форматами.
Parsing Reliability Patterns (2026-03)
| Language / Format | Structural Signal | Common Bottleneck |
|---|---|---|
| Chinese / Cantonese | Explicit punctuation (Персонаж: реплика) | Format consistency |
| Japanese | Stable quotation markers | Minor formatting variations |
| English (US/UK) | Implicit layout structure | Indentation and capitalization |
| German / French | Complex theatrical formatting | Ambiguous block boundaries |
4. Скрытая стоимость преобразования скриптов в простой текст
Многие системы субтитров обрабатывают скрипты, сначала преобразуя документы в простой текст, удаляя информацию о макете.
Исходный отформатированный скрипт:
ГАМЛЕТ Быть или не быть
После преобразования в простой текст:
ГАМЛЕТ Быть или не быть
Без отступа или границ блоков парсер должен полагаться на семантическое угадывание, чтобы определить, является ли «ГАМЛЕТ» именем персонажа или частью предложения.
5. Архитектурный поворот: разбор на основе макета
Вместо того, чтобы спрашивать: «Что означает это предложение?», машина спрашивает: «Как выглядит этот текстовый блок геометрически?»
Используя извлечение OOXML из файлов .docx, мы получаем точные атрибуты макета, такие как отступ (измеренный в твипах), флаги капитализации и стили абзацев.
Пример: Сигналы макета, извлеченные из скрипта
Блок A:
indent = 72pt,caps_ratio = 1.0,line_length = 8- → Классифицируется как Персонаж
Блок B:
indent = 36pt,caps_ratio = 0.2,line_length = 48- → Классифицируется как Диалог
6. Сценические направления: когда типография становится структурой
Во многих театральных скриптах сценические направления указываются исключительно с помощью типографии — часто курсивом.
Пример: Типография как структура
ГАМЛЕТ Быть или не быть.
Он делает паузу и смотрит в зал.
ОФЕЛИЯ Мой лорд?
| Блок | Интерпретация |
|---|---|
| ГАМЛЕТ | Имя персонажа |
| Предложение с отступом | Диалог |
| Курсивный текст | Сценическое направление |
Как только форматирование исчезает, парсер не может различить диалог и повествование. В некоторых скриптах используются еще более минимальные курсивные заметки:
пауза отворачивается
Они почти не содержат лингвистических подсказок, полагаясь на 100% на атрибуты типографского стиля, такие как italic=true.
7. Трехуровневая модель искусственного интеллекта для надежного обнаружения реплик
Мы перепозиционировали ИИ как рецензента, а не как угадывателя:
- Уровень 1 — Детерминированные правила: Обрабатывает явные форматы со 100% точностью.
- Уровень 2 — Проверка ИИ: Действует как корректор для проверки неопределенных классификаций.
- Пример:
ГАМЛЕТ (тихо). Система определяет, является ли «(тихо)» сценическим направлением или диалогом, на основе контекста документа.
- Пример:
- Уровень 3 — Классификация ИИ: Полная классификация для очень неоднозначных областей, основанная на шаблонах макета, найденных в других местах того же документа.
Заключение
Театральные скрипты кажутся простыми, но их смысл возникает из пространственной организации. Переходя от семантического угадывания к разбору на основе макета, SurtitleLive предоставляет правильный субтитр в нужный момент.
FAQ
В: Что такое субтитр в театре? О: Субтитр — это момент, когда строка диалога должна появиться на дисплее субтитров. Обнаружение реплик требует идентификации блоков диалога и переходов между говорящими в скрипте.
В: Как система обрабатывает непоследовательное форматирование? О: Наша система кластеризует похожие макеты. Если профиль документа меняется, парсер выполняет сегментацию макета, чтобы адаптировать свою стратегию в режиме реального времени.
В: Почему макет важен при разборе скриптов для субтитров? О: Многие скрипты используют отступ и интервал вместо пунктуации для кодирования структуры. Парсер на основе макета обнаруживает реплики более надежно, чем одни только семантические модели.