เรขาคณิตของการแยกวิเคราะห์บทละคร: ระบบคำบรรยายและการฉายอักษรเหนือเวทีตรวจจับบทสนทนาได้อย่างไร
ระบบคำบรรยายสำหรับโรงละครสมัยใหม่ขึ้นอยู่กับความสามารถที่สำคัญอย่างหนึ่ง: การตรวจจับคิวจากบทละครได้อย่างแม่นยำ
ไม่ว่าจะสร้างการฉายอักษรเหนือเวทีสำหรับโอเปร่า คำบรรยายสำหรับการแสดงบนเวที หรือคำบรรยายสดเพื่อการเข้าถึง ระบบจะต้องกำหนดได้อย่างน่าเชื่อถือ:
- ใครกำลังพูด
- เมื่อใดที่บทพูดเริ่มขึ้น
- กลุ่มบทสนทนาปรากฏที่ใดในบทละคร
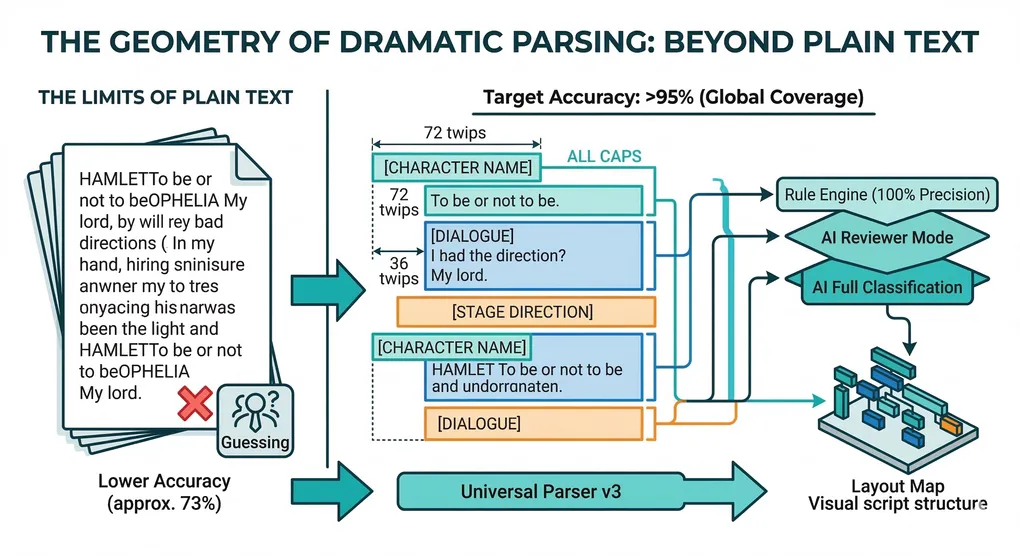
เมื่อมองแวบแรก สิ่งนี้ฟังดูเหมือนเป็นปัญหาการประมวลผลภาษาธรรมชาติ ในทางปฏิบัติไม่ใช่ ระหว่างการพัฒนา SurtitleLive v2 เราได้วิเคราะห์บทละครเกือบ 100 เรื่องจากภาษาและขนบธรรมเนียมการละครที่แตกต่างกัน กระบวนการนั้นนำเราไปสู่ข้อสรุปที่น่าประหลาดใจ: บทละครไม่ใช่ข้อมูลทางภาษาเป็นหลัก แต่เป็นข้อมูลเชิงพื้นที่
1. ปัญหาบทละครตะวันตก: โครงสร้างที่ไม่มีเครื่องหมายวรรคตอน
บทละครภาษาอังกฤษทั่วไปอาศัยแบบแผนการจัดวางมากกว่าเครื่องหมายวรรคตอนเพื่อกำหนดบทบาท
ตัวอย่าง: รูปแบบบทละครเวทีทั่วไป
แฮมเล็ต เป็นหรือไม่เป็น นั่นคือปัญหา
โอฟีเลีย ท่านลอร์ด ข้าพเจ้ามีความทรงจำของท่าน
สำหรับผู้อ่านที่เป็นมนุษย์ การตีความนั้นชัดเจน:
| บล็อก | การตีความ |
|---|---|
| แฮมเล็ต | ชื่อตัวละคร |
| ข้อความเยื้อง | บทพูด |
| โอฟีเลีย | ชื่อตัวละคร |
แต่สำหรับตัวแยกวิเคราะห์ที่เห็นเพียงข้อความธรรมดา โครงสร้างจะหายไป เราจดจำรูปแบบได้เพราะชื่อตัวละครปรากฏเป็น ตัวพิมพ์ใหญ่ทั้งหมด บทพูด เยื้อง และบล็อกถูกคั่นด้วยช่องว่างแนวตั้ง ไวยากรณ์ของบทละครตะวันตกเป็นแบบการพิมพ์ ไม่ใช่ภาษา
2. จากบล็อกบทละครสู่คิวคำบรรยาย
ในสภาพแวดล้อมการแสดงสด ซอฟต์แวร์คำบรรยายไม่ได้เพียงแค่แสดงข้อความ แต่จะต้องแปลงบทละครเป็นลำดับของ คิวคำบรรยาย
แต่ละบล็อกบทสนทนาที่ตรวจพบจะกลายเป็นคิวคำบรรยายที่สามารถเรียกใช้ได้ระหว่างการแสดงสด หากตัวแยกวิเคราะห์ระบุบล็อกบทสนทนาผิด ระบบคำบรรยายจะเรียกใช้คิวที่ไม่ถูกต้อง ซึ่งเป็นความล้มเหลวที่ยอมรับไม่ได้ในโรงละครสด
3. เครื่องหมายวรรคตอนเทียบกับการจัดวาง: การค้นพบข้ามภาษา
การแสดงจะแตกต่างกันอย่างมากขึ้นอยู่กับการพึ่งพาเครื่องหมายที่ชัดเจนเทียบกับเครื่องหมายโดยนัยของภาษา
จีน / กวางตุ้ง: ขับเคลื่อนด้วยเครื่องหมายวรรคตอน
บทละครจีนมักจะเข้ารหัสโครงสร้างอย่างชัดเจน:
มาลี: วันนี้ฝนตก นนท์: จริงหรือ? (ทั้งสองมองออกไปนอกหน้าต่าง)
| รูปแบบ | การจำแนกประเภท |
|---|---|
| ตัวละคร: บทพูด | บทพูด |
| (...) (วงเล็บ) | คำแนะนำเวที |
โครงสร้างที่ขับเคลื่อนด้วยเครื่องหมายวรรคตอนนี้ทำให้การแยกวิเคราะห์เกือบจะง่ายเมื่อเทียบกับรูปแบบตะวันตก
ความแม่นยำในการแยกวิเคราะห์เปรียบเทียบ (2026-03)
| ภาษา / รูปแบบ | ความแม่นยำโดยประมาณ | สัญญาณโครงสร้างหลัก | คอขวดในการแยกวิเคราะห์ |
|---|---|---|---|
| จีน / กวางตุ้ง | ~100% | เครื่องหมายวรรคตอนที่ชัดเจน (ตัวละคร: บทพูด) | ไม่มี |
| ญี่ปุ่น | ~98% | เครื่องหมายอัญประกาศที่เสถียร | รูปแบบที่แตกต่างกันเล็กน้อย |
| อังกฤษ (US/UK) | ~73% | โครงสร้างการจัดวางโดยนัย | การเยื้องและการใช้ตัวพิมพ์ใหญ่ |
| เยอรมัน / ฝรั่งเศส | ~71% | รูปแบบการละครที่ซับซ้อน | ขอบเขตบล็อกที่ไม่ชัดเจน |
4. ค่าใช้จ่ายแอบแฝงของการแปลงบทละครเป็นข้อความธรรมดา
ระบบคำบรรยายจำนวนมากประมวลผลบทละครโดยแปลงเอกสารเป็นข้อความธรรมดาก่อน โดยลบข้อมูลการจัดวางออก
บทละครที่มีรูปแบบเดิม:
แฮมเล็ต เป็นหรือไม่เป็น
หลังจากการแปลงเป็นข้อความธรรมดา:
แฮมเล็ต เป็นหรือไม่เป็น
หากไม่มีการเยื้องหรือขอบเขตบล็อก ตัวแยกวิเคราะห์จะต้องอาศัย การคาดเดาเชิงความหมาย เพื่อพิจารณาว่า "แฮมเล็ต" เป็นชื่อตัวละครหรือเป็นส่วนหนึ่งของประโยค
5. จุดเปลี่ยนทางสถาปัตยกรรม: การแยกวิเคราะห์แบบเน้นโครงร่างเป็นอันดับแรก
แทนที่จะถามว่า "ประโยคนี้หมายความว่าอย่างไร" เครื่องจะถามว่า: "บล็อกข้อความนี้มีลักษณะทางเรขาคณิตอย่างไร"
โดยใช้ การแยก OOXML จากไฟล์ .docx เราจะดึงแอตทริบิวต์การจัดวางที่แม่นยำ เช่น การเยื้อง (วัดเป็นทวิป) แฟล็กการใช้ตัวพิมพ์ใหญ่ และสไตล์ย่อหน้า
ตัวอย่าง: สัญญาณการจัดวางที่ดึงมาจากบทละคร
บล็อก A:
indent = 72pt,caps_ratio = 1.0,line_length = 8- → จัดประเภทเป็นตัวละคร
บล็อก B:
indent = 36pt,caps_ratio = 0.2,line_length = 48- → จัดประเภทเป็นบทพูด
6. คำแนะนำเวที: เมื่อการพิมพ์กลายเป็นโครงสร้าง
ในบทละครหลายเรื่อง คำแนะนำเวทีจะถูกระบุโดยการพิมพ์เท่านั้น ซึ่งมักจะเป็น ตัวเอียง
ตัวอย่าง: การพิมพ์เป็นโครงสร้าง
แฮมเล็ต เป็นหรือไม่เป็น
เขาหยุดและมองไปที่ผู้ชม
โอฟีเลีย ท่านลอร์ด?
| บล็อก | การตีความ |
|---|---|
| แฮมเล็ต | ชื่อตัวละคร |
| ประโยคเยื้อง | บทพูด |
| ข้อความตัวเอียง | คำแนะนำเวที |
เมื่อการจัดรูปแบบหายไป ตัวแยกวิเคราะห์จะไม่สามารถแยกแยะระหว่างบทพูดและคำบรรยายได้ บทละครบางเรื่องใช้โน้ตตัวเอียงที่น้อยกว่านั้นอีก:
หยุด หันไป
สิ่งเหล่านี้แทบไม่มีสัญญาณทางภาษาเลย โดยอาศัยแอตทริบิวต์สไตล์การพิมพ์ 100% เช่น italic=true
7. โมเดล AI สามระดับสำหรับการตรวจจับคิวที่เชื่อถือได้
เราปรับตำแหน่ง AI ใหม่ให้เป็นผู้ตรวจสอบมากกว่าผู้คาดเดา:
- ระดับ 1 — กฎเชิงกำหนด: จัดการรูปแบบที่ชัดเจนด้วยความแม่นยำ 100%
- ระดับ 2 — การตรวจสอบโดย AI: ทำหน้าที่เป็นผู้พิสูจน์อักษรเพื่อตรวจสอบความถูกต้องของการจำแนกประเภทที่ไม่แน่นอน
- ตัวอย่าง:
แฮมเล็ต (อย่างเงียบๆ)ระบบจะพิจารณาว่า "(อย่างเงียบๆ)" เป็นคำแนะนำเวทีหรือบทพูดโดยอิงตามบริบทของเอกสาร
- ตัวอย่าง:
- ระดับ 3 — การจำแนกประเภทโดย AI: การจำแนกประเภทแบบเต็มสำหรับภูมิภาคที่ไม่ชัดเจนอย่างมาก โดยยึดตามรูปแบบการจัดวางที่พบที่อื่นในเอกสารเดียวกัน
สรุป
บทละครดูเหมือนง่าย แต่ความหมายของมันเกิดขึ้นจากการจัดระเบียบเชิงพื้นที่ โดยการเปลี่ยนจากการคาดเดาเชิงความหมายเป็นการแยกวิเคราะห์แบบเน้นโครงร่างเป็นอันดับแรก SurtitleLive มอบ คิวคำบรรยายที่ถูกต้อง ในเวลาที่เหมาะสม
คำถามที่พบบ่อย
ถาม: คิวคำบรรยายในโรงละครคืออะไร ตอบ: คิวคำบรรยายคือช่วงเวลาที่บทพูดควรปรากฏบนจอแสดงผลคำบรรยาย การตรวจจับคิวต้องระบุบล็อกบทสนทนาและการเปลี่ยนผู้พูดภายในบทละคร
ถาม: ระบบจัดการกับการจัดรูปแบบที่ไม่สอดคล้องกันอย่างไร ตอบ: ระบบของเราจัดกลุ่มการจัดวางที่คล้ายกัน หากโปรไฟล์เอกสารเปลี่ยนแปลง ตัวแยกวิเคราะห์จะทำการแบ่งส่วนการจัดวางเพื่อปรับกลยุทธ์แบบเรียลไทม์
ถาม: เหตุใดการจัดวางจึงมีความสำคัญเมื่อแยกวิเคราะห์บทละครสำหรับคำบรรยาย ตอบ: บทละครจำนวนมากใช้การเยื้องและช่องว่างแทนเครื่องหมายวรรคตอนเพื่อเข้ารหัสโครงสร้าง ตัวแยกวิเคราะห์แบบเน้นโครงร่างเป็นอันดับแรกจะตรวจจับคิวได้อย่างน่าเชื่อถือมากกว่าโมเดลเชิงความหมายเพียงอย่างเดียว