スクリプト解析の幾何学:演劇字幕・スーパータイトルにおける対話の検出方法
現代の演劇字幕システムは、スクリプトからの正確なキュー検出という重要な機能に依存しています。
オペラ用のスーパータイトル、舞台作品用の字幕、アクセシビリティのためのライブキャプションの生成など、システムは以下を確実に判断する必要があります。
- 誰が話しているか
- セリフがいつ始まるか
- 対話ブロックがスクリプトのどこにあるか
一見すると、これは自然言語処理の問題のように思えます。しかし実際にはそうではありません。SurtitleLive v2の開発中に、さまざまな言語や演劇の伝統からの約100のスクリプトを分析しました。その結果、驚くべき結論に達しました。演劇のスクリプトは、主に言語データではなく、空間データであるということです。
1. 西洋のスクリプトの問題:句読点のない構造
典型的な英語の演劇スクリプトは、役割を定義するために句読点ではなくレイアウトの慣習に依存しています。
例:典型的な舞台スクリプトのレイアウト
HAMLET To be, or not to be: that is the question.
OPHELIA My lord, I have remembrances of yours.
人間が読めば、解釈は明らかです。
| Block | 解釈 |
|---|---|
| HAMLET | 登場人物名(character) |
| インデントされたテキスト | セリフ(dialogue) |
| OPHELIA | 登場人物名(character) |
しかし、プレーンテキストしか認識しないパーサーにとっては、構造が失われます。登場人物名(character)がすべて大文字で表示され、セリフ(dialogue)がインデントされ、ブロックが垂直方向に間隔を空けて区切られているため、パターンを認識できます。西洋のスクリプトの文法は、言語的ではなく、タイポグラフィ的です。
2. スクリプトブロックから字幕キューへ
ライブパフォーマンス環境では、字幕ソフトウェアは単にテキストを表示するだけではありません。スクリプトを字幕キューのシーケンスに変換する必要があります。
検出された各対話ブロックは、ライブパフォーマンス中にトリガーできる字幕キューになります。パーサーが対話ブロックを誤って識別した場合、字幕システムは間違ったキューをトリガーします。これはライブシアターでは許容できない失敗です。
3. 句読点 vs. レイアウト:異言語間の発見
パフォーマンスは、言語が明示的なマーカーに依存するか、暗黙的なマーカーに依存するかによって大きく異なります。
中国語/広東語:句読点駆動
中国語の演劇スクリプトは、構造を明示的にエンコードすることがよくあります。
太郎:今日は雨です。 花子:本当ですか? (二人は窓の外を見る)
| Pattern | 分類 |
|---|---|
| 登場人物:台詞 | セリフ(dialogue) |
| (...) (Parentheses) | 舞台指示(stage direction) |
この句読点駆動の構造により、西洋の形式と比較して、解析がほぼ簡単になります。
解析の信頼性パターン(2026-03)
| 言語 / 形式 | 構造シグナル | よくあるボトルネック |
|---|---|---|
| 中国語 / 広東語 | 明示的な句読点(登場人物:台詞) | 形式の一貫性 |
| 日本語 | 安定した引用符 | 軽微なフォーマット差 |
| 英語(US/UK) | 暗黙のレイアウト構造 | インデントと大文字 |
| ドイツ語 / フランス語 | 複雑な劇場書式 | ブロック境界の曖昧さ |
4. スクリプトをプレーンテキストに変換する隠れたコスト
多くの字幕システムは、最初にドキュメントをプレーンテキストに変換し、レイアウト情報を削除してスクリプトを処理します。
元の書式設定されたスクリプト:
HAMLET To be or not to be
プレーンテキスト変換後:
HAMLET To be or not to be
インデントやブロック境界がない場合、パーサーは「HAMLET」が人物名(character)なのか、文の一部なのかを判断するために意味推測に頼る必要があります。
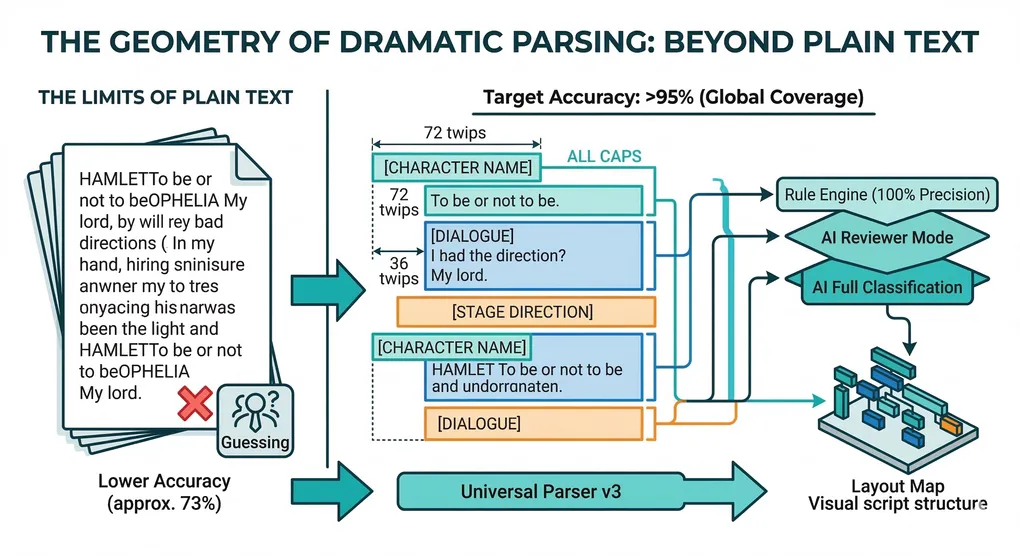
5. アーキテクチャのピボット:レイアウト優先解析
「この文はどういう意味ですか?」と尋ねる代わりに、マシンは**「このテキストブロックは幾何学的にどのように見えますか?」**と尋ねます。
.docxファイルからOOXML抽出を使用することにより、インデント(twipsで測定)、大文字化フラグ、段落スタイルなどの正確なレイアウト属性を取得します。
例:スクリプトから抽出されたレイアウト信号
Block A:
indent = 72pt,caps_ratio = 1.0,line_length = 8- → 登場人物(Character)として分類
Block B:
indent = 36pt,caps_ratio = 0.2,line_length = 48- → セリフ(Dialogue)として分類
6. 舞台指示:タイポグラフィが構造になるとき
多くの演劇スクリプトでは、舞台指示は純粋にタイポグラフィ(多くの場合イタリック体)によって示されます。
例:構造としてのタイポグラフィ
HAMLET To be, or not to be.
He pauses and looks toward the audience.
OPHELIA My lord?
| Block | 解釈 |
|---|---|
| HAMLET | 登場人物名(character) |
| インデントされた文 | セリフ(dialogue) |
| イタリック体のテキスト | 舞台指示(stage direction) |
書式設定が消えると、パーサーはセリフ(dialogue)とナレーションを区別できません。一部のスクリプトでは、さらに最小限のイタリック体のメモを使用します。
pause turns away
これらには言語的な手がかりがほとんど含まれておらず、italic=trueのようなタイポグラフィスタイルの属性に100%依存しています。
7. 信頼性の高いキュー検出のための3層AIモデル
AIを推測者ではなくレビュー担当者として再配置しました。
- Tier 1 — 決定論的ルール: 明示的な形式を100%の精度で処理します。
- Tier 2 — AIレビュー: 不確かな分類を検証するための校正者として機能します。
- 例:
HAMLET (quietly). システムは、「(quietly)」が舞台指示(stage direction)であるか、セリフ(dialogue)であるかを、ドキュメントのコンテキストに基づいて判断します。
- 例:
- Tier 3 — AI分類: 同じドキュメント内の他の場所で見つかったレイアウトパターンによって固定された、非常にあいまいな領域の完全な分類。
結論
演劇スクリプトは単純に見えますが、その意味は空間的な構成から生まれます。意味推測からレイアウト優先解析に移行することで、SurtitleLiveは適切な字幕キューを、適切なタイミングで提供します。
FAQ
Q: 演劇における字幕キューとは何ですか? A: 字幕キューとは、セリフ(dialogue)が字幕表示に表示されるべき瞬間です。キュー検出には、スクリプト内の対話ブロックと話者の切り替えを識別する必要があります。
Q: システムは一貫性のない書式設定をどのように処理しますか? A: 当社のシステムは、同様のレイアウトをクラスタリングします。ドキュメントプロファイルが変更された場合、パーサーはレイアウトセグメンテーションを実行して、戦略をリアルタイムで適応させます。
Q: 字幕のスクリプトを解析する際にレイアウトが重要なのはなぜですか? A: 多くのスクリプトでは、構造をエンコードするために句読点の代わりにインデントと間隔を使用します。レイアウト優先パーサーは、セマンティックモデルのみよりも確実にキューを検出します。